現代の企業において、業務効率化は重要な課題の一つです。その中で注目されているのがOCR技術。書類のデジタル化を通じて、膨大なデータを効率的に処理できる可能性を秘めています。しかし、導入を検討する際に気になるのが「実際の精度はどれほどのものか?」という点です。本コラムでは、実際にOCRを使って様々な状況下でどこまで読み取れるかを検証します。具体的なポイントや事例を交え、OCRの実力と可能性をご紹介します。

はじめに:OCRとは?基本的な仕組みと利用方法
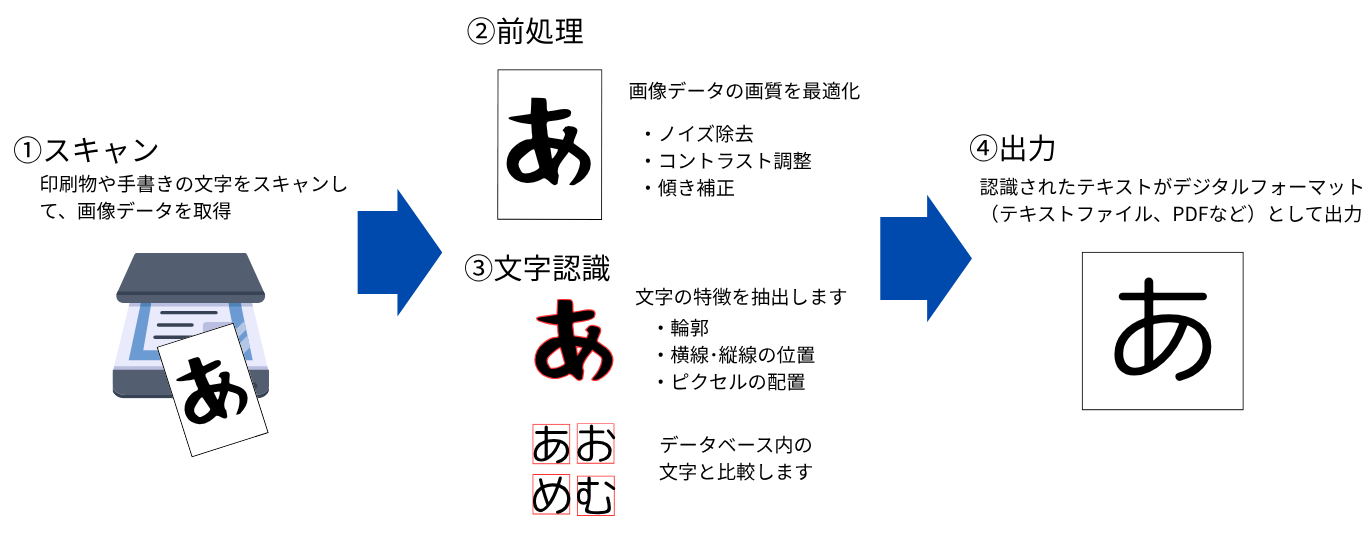
OCR技術の仕組み
どうやって業務に活用できる?
OCRが苦手とする文字とは?
苦手な文字や状況
難解だったり特殊すぎる文字
筆跡の個人差や極端に崩れた文字などのバラツキや、画数が多く細部が潰れている文字は認識できない場合もあります。また、常用外の難読漢字といったデータベースに存在しない文字は、認識できません。
文書自体の劣化や加工が施されている
紙やインクの劣化により文字と背景のコントラストが低下すると、正常な認識が難しくなります。また、下線やハイライトが引かれていたり、紙自体に光沢加工が施されていると認識が難しくなる場合があります。
背景と技術的制約
パターンマッチングの限界
OCRの基本的なアルゴリズムは、既知の文字パターン(標準フォント)と入力画像から抽出されたパターンを比較するものが多いです。微妙な違いや汚れ、手書きの不規則性は、極めて類似した認識が難しいです。
データセットの限界
機械学習モデルはトレーニングデータに依存します。トレーニングされたデータセットが特定の種類の文字を十分に含んでいない場合、認識精度が低下します。
OCRの精度検証!


検証1 目視でも十分読める文字
書いた文字
読み取り結果
検証2 少し読みづらい長文の文章
書いた文字
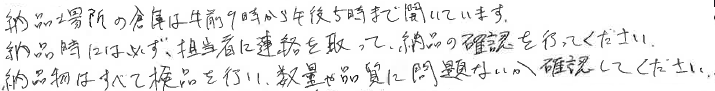
読み取り結果

検証3 難読漢字
書いた文字

読み取り結果

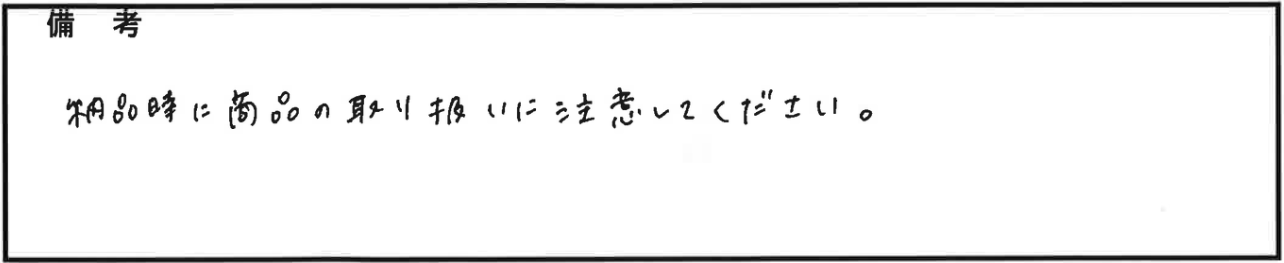
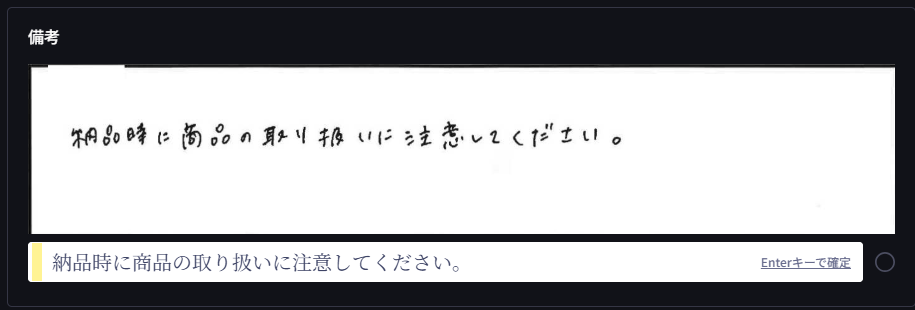
検証4 朱インク汚れ
書いた文字

書いた文字(2行目):P3861
読み取り結果

読み取り結果(2行目):P3861
検証結果
検証の結果、OCRの読み取りには、以下のような特徴があることがわかりました。
OCR精度向上につながる3つのポイント
OCR技術は、デジタル化の進行に伴い、その重要性がますます高まっています。うまく運用することで、データ入力の自動化や検索性の向上、そしてアーカイブの効率化が実現し、組織全体の生産性向上につながります。今回は、OCR精度を高めるためのポイントについて詳しく解説し、そのメリットを最大限に引き出すための具体的なアプローチを紹介します。
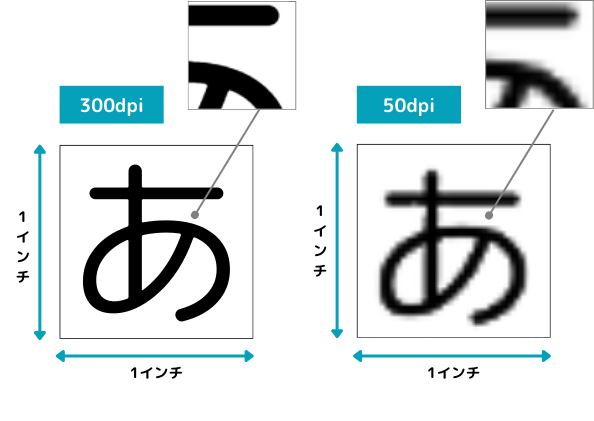
01 スキャン解像度を高く設定する
OCRの精度を高めるためには、スキャン画像の品質が非常に重要です。特に、300~400dpi程度の解像度が推奨されており、文字の細部までしっかり読み取れることで認識精度が向上します。高解像度でスキャンすることで、文字の輪郭や細かい印刷が鮮明になり、手書き文字や小さな文字も正確に読み取れるようになります。ただし、ホチキス留めや糊付けされている紙の書類は、スキャンできないことが多く、OCRには向きません。そのため、スキャンする前に読み取り対象の状態を確認することが重要です。
02 画像前処理の活用
OCRの精度は、画像の前処理によっても大きく変わります。具体的には、コントラスト調整・ノイズ除去・シャープ化などの処理が有効です。これらの処理はOCRソフトで行うこともできます。
前処理を行うことで、文字と背景の差がはっきりし、誤認識を減らすことができます。特に手書きやスキャン品質が不安定な場合に効果的です。
03 OCRソフトの選定
OCRの効果を最大限に活かすには、業務に合ったソフトの選定と、データ取得の自動化がカギです。手書き文字や多言語対応が必要な場合には、専門性の高いソフトを選ぶことで、精度の高い読み取りと作業効率の向上が期待できます。
また、複数帳票が整理されていない状態でも、OCRに自動仕分け機能が付いていれば、手間がかかりません。さらに、自動化機能と組み合わせることで、入力作業の削減や業務スピードの向上にもつながります。
今回の検証で使用したOCR製品

NSW-OCRは手書き書類や帳票の文字を識別し、自動でデータ化するサービスです。
96.77%の高精度読み取りと自動処理を組み合わせることで、飛躍的な効率化とペーパーレス化を支援します。
機能・特徴
活用事例
当社総務人事部にて履歴書や保証書、振込依頼書など、入社に関わる書類750枚分のデータ入力を想定したところ、従来の手作業では約100時間かかっていた作業が、AI-OCRの活用により28時間まで短縮できました。
入力ミスも大幅に減少し、作業品質の向上にもつながっています。
導入当初は職員への教育が必要でしたが、運用効果が高く、現在では他部門への展開も進んでいます。
他ユースケース
物流業界では、伝票や出荷指示書をOCRで読み取ることで、手入力の手間を削減し、出荷処理のスピードと正確性を向上させています。これにより、作業効率の改善だけでなく、ヒューマンエラーの防止にもつながっています。また、小売業界では、仕入伝票や棚卸表のデータ化にOCRを活用し、在庫管理の精度を高め、売上分析や需要予測への応用が進んでいます。こうした取り組みは、現場の業務負荷軽減と経営判断の迅速化を同時に実現しています。
おわりに:OCR導入の未来と今後の可能性
OCR技術は今後、AIとの連携を通じてさらなる進化を遂げ、業務の効率化だけでなく、企業の意思決定や戦略策定にも大きく貢献していくと考えられます。本コラムを通じて、OCRの可能性を少しでも具体的に感じていただけたなら幸いです。

現在、無償トライアルのご案内も行っておりますので、ご興味をお持ちの方はぜひこちらのフォームよりお問い合わせください。業務改革への第一歩として、ぜひこの機会をご活用ください。
