
AIを導入したものの、「モデルは作れたのに、現場ではほとんど使われていない」と感じていませんか?多くの企業で、PoCは成功しても“現場定着”で止まってしまうのが現実です。高性能なモデルやエージェントを構築できても、“必要な時に安定して使えないAI”は、業務では役に立ちません。本記事では、なぜAIが“作っただけで終わってしまう”のかを整理し、さらに、Databricksを活用して、AIを運用し続けるための実践的なアプローチを解説します。
AIが作っただけで終わってしまうのはなぜか
生成AIが一般化した今、多くの企業が「試作(PoC)は成功しても、本番で使われない」という壁にぶつかっています。その原因は、単なる技術不足ではなく、「作る労力」と「使い続ける労力」の間に深い溝があるからです。特に最近は、社内データを検索して回答を生成するRAG(検索拡張生成)の活用が進んでいますが、こうした仕組みほど運用設計の差がそのまま現場負荷に直結します。



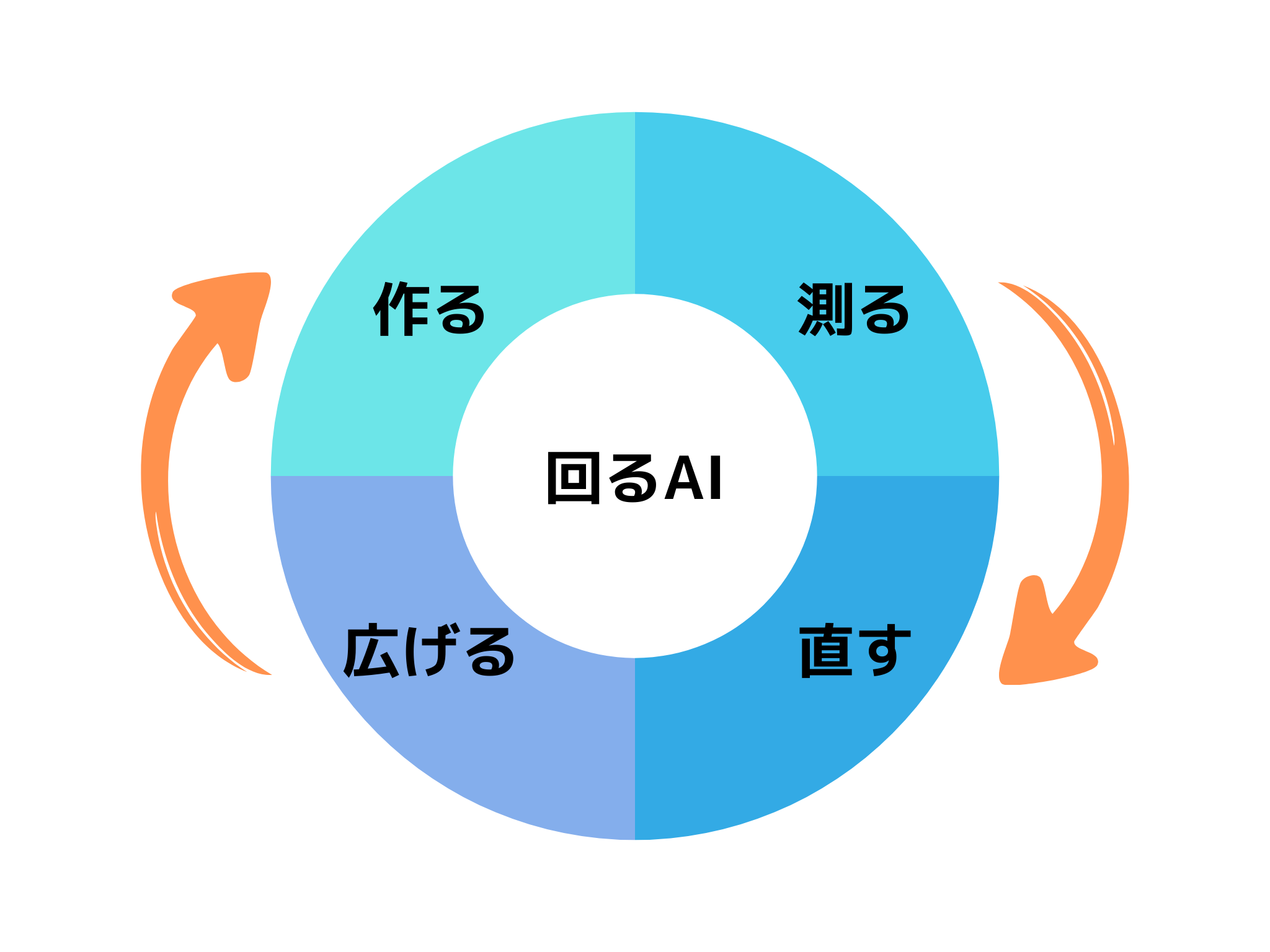
どれだけ優れたモデルを作れても、「作る・測る・直す・広げる」が別々の場所に散らばっている限り、この溝は本質的に埋まりません。
AIの性能ではなく、構造そのものが限界を決めてしまうのです。
使われるAIの本質
AIが現場で「相棒」として認められ、使われ続けるためには、単に賢いだけでは不十分です。そこには、ビジネスの現場に耐えうる4つの必須条件があります。
現場が求める「4つの条件」

(即戦力)

(可視化)

(柔軟性)
(持続性)
「一つの基盤」で循環させるという近道
これらの条件をバラバラのツールで実現しようとすると、工程の間に
「壁」ができ、スピードも精度も落ちてしまいます。最短ルートは、
「作る→測る→直す→広げる」というサイクルを一つの基盤(プラット
フォーム)の上で循環させることです。もしこのサイクルが複数のツ
ールにまたがると、どこかの工程で必ず摩擦が発生し、改善スピード
は鈍化します。改善のたびにツール間の連携・権限・データ同期が発
生する構造では、AIは“直す速度”で人間に負けてしまうからです。
この後紹介するDatabricksの役割としては、エージェントを設計し
てすぐに試せるスピード感、改善プロセスを管理する透明性、そして
データが増えてもコストを抑える最適化技術を、バラバラの点ではなく
「連続したワークフロー」として提供します。AIを単体のツールとし
て置くのではなく、データの管理から修正までを一つの円のように回
す。この「循環する仕組み」こそが、AIを「作る」から「回す」へ転
換するための実践的なアプローチだといえます。
「回るAI」を成立させるための設計思想と構造
ここまでで見てきた通り、AI活用がPoC止まりになる本質的な理由は、モデルの性能不足ではなく、「設計思想の不足」にあります。
では、現場で使われ続けるAIは、どのような前提で設計されているのでしょうか。
従来のAI開発は、「精度の高いモデルを作ること」をゴールに設計されてきました。しかし、現場で使われるAIに必要なのは完成度の高さではなく、継続して運用できる構造です。本記事では、こうした継続的に改善しながら現場で使われ続けるAIを「回るAI」と呼びます。回すことを設計思想に据えた瞬間、基盤の選択肢は自然と絞られます。工程が分断された構成では、運用そのものが止まりやすくなるためです。つまり、回るAIの設計思想とは、完成品を作ることではなく、それを回し続けるための運転体制をどう設計するかにあります。具体的には、次の4つが最初から設計に組み込まれている必要があります。
回るAIを支える4つの設計要件
設計、実装、評価、デプロイが別々のツールやチームに分かれていると、改善サイクルは必ず鈍化します。現場で使われるAIには、「素早く作り、すぐに現場へ出せる」ことを前提とした構造が必要です。
精度、応答速度、コストが見えないAIは、現場にとって「信用できないブラックボックス」になってしまいます。AIの挙動は常に可視化され、判断材料として共有・説明できる状態である必要があります。
RAGにおいて重要なのは、「検索できるかどうか」ではありません。本当に問われるのは、データや利用者が増えても、壊れずに回り続けるかです。そのためには、データ量・利用者数の増加を前提にした検索・管理構造が不可欠となります。
特定のプロンプト職人や、一部の担当者に依存したAIは、その人がいなくなった瞬間に止まってしまいます。回るAIには、標準化された手順で、誰でも直せることが持続性の条件として求められます。
なぜDatabricksは「回るAI」の基盤になり得るのか
重要なのは、Databricksの強みが個々の機能性能ではなく、設計思想そのものにある点です。Databricksは、データ管理・モデル開発・評価・運用を分断せず扱うことを前提に設計された、数少ない統合基盤です。そのため、「回るAI」に必要な設計要件を一つの基盤上で満たせる構造になっています。これはDatabricksが優れているから選ぶという話ではありません。回し続けるAIを前提にすると、分断しない基盤という要件が必然的に残るということです。この条件を満たせない構成では、運用段階で改善が止まりやすくなります。結果として、設計時点で選択肢から外れていきます。その必然の条件を満たす構造の一例として、Databricksが位置づきます。以下では、「回るAIの設計要件」に対してDatabricksの各機能がどう対応するのかを整理します。
Databricksで実現する「回るAI」の仕組み
Databricksは、以下の3つの技術により、単機能ツールを組み合わせるだけでは到達しづらい連続したワークフローを提供します。重要なのは、これらが部分最適なツールの寄せ集めではなく、「回るAI」という思想に沿って一体設計されている点です。そのため、改修やスケールも基盤の中で連続的に完結できる構造になっています。以下では、この設計を支える3つの要素を順に見ていきます。
※クリックすると機能内容が表示されます
▷
▷
・本番投入までの時間を短縮
・セキュリティを最初から統合
・改善前提の設計
・運用中の性能を監視
・ブラックボックス化を防止
・データに基づく改善
・Unity Catalogと完全統合
・数千億件規模でも高速検索
・自動最適化で運用負荷削減
現場で使われ続ける、AIを目指して
AIの導入は、完成がゴールではありません。そこからが本当のスタートです。重要なのは、高性能なAIを一度で作ることではなく、改善し続けられる設計と構造を備えることにあります。Databricksは、「AIを回す」という思想をアーキテクチャとして実装したプラットフォームです。そのため、単なる機能選定ではなく、AI活用の必然として選ばれる基盤になっています。回るAIの要件を積み上げていくと、分断しない統合基盤という条件だけが残り、自然とDatabricksという解に行き着きます。これは製品選びではなく、設計思想の帰結です。
まずは現状の課題を整理するところからでも構いません。次の一歩として、何が最適かを一緒に整理してみませんか?
「とりあえず作った」で終わらせず、「現場が使い続ける」文化へ。
もし、次のような課題を少しでも感じていらっしゃるなら、私たちがお手伝いできます。
「実務で使えるレベルのエージェントを、一刻も早く立ち上げたい」
「プロンプトやモデルの管理、安全な運用ルールを整えたい」
「RAGのコストや遅延を抑え、安定してスケールさせたい」
大がかりな準備は不要です。現在の業務要件やデータの状況を共有いただくだけで、現実的なステップをご提案します。AIをビジネスの確かな武器にするために、まずは気軽なご相談から始めてみませんか。
